
Методиквыделения правдоподобных гипотез в INTERNIST
В процессе выполнения консультаций программа INTERNIST работает следующим образом. Сначала пользователь вводит список существующих проявлений заболеваний пациента. Каждое проявление активизирует один или несколько узлов в дереве заболеваний.
Из выделенных на этом этапе узлов программа формирует модели заболевания, каждая из которых включает четыре списка:
(1) наблюдаемые проявления, не связанные с данным заболеванием;
(2) наблюдаемые проявления, согласующиеся с данным заболеванием;
(3) проявления, отсутствующие во введенных данных, но всегда сопутствующие данному заболеванию;
(4) проявления, которые отсутствуют во введенных данных, но не согласуются с данным заболеванием (опровергают выдвинутую гипотезу).
В модели заболевания проявления, подтверждающие гипотезу, получают положительные оценки, а те, которые им противоречат, — отрицательные. Оба типа оценок "взвешиваются" значениями свойств IMPORT соответствующих проявлений, и модель получает премиальные очки, если имеет причинную связь с другим подтвержденным заболеванием. Затем модели заболеваний разделяются на две группы. В одну группу попадают модель с самой высокой оценкой и все остальные, которые представляют взаимно исключающие с ней гипотезы. Их можно считать "соседними" узлами на дереве заболеваний. Другая группа включает заболевания, совместимые с наиболее правдоподобной гипотезой, т.е. узлы, принадлежащие другим областям заболеваний (рис. 13.2).
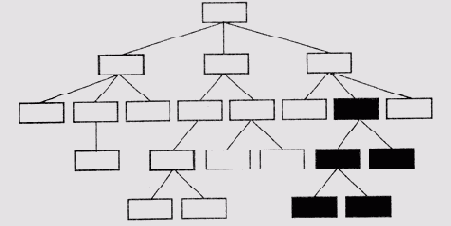
Рис. 13.2. Разделение узлов в дереве гипотез. Узлы активизированных гипотез вычерчены утолщенными прямоугольниками, а узел наиболее правдоподобной гипотезы и его дочерние узлы залиты серым цветом
В таком разделении используется концепция доминирования, которой придается следующий смысл. Модель заболевания D1 доминирует над D2 в том случае, если наблюдаемые проявления, которые не могут быть объяснены гипотезой D1, входят как подмножество в число проявлений, которые не объясняются и гипотезой D2. Если мы выделили наиболее правдоподобную гипотезу D0 среди всех активизированных на первом этапе, то каждая из остальных гипотез Di сравнивается с гипотезой Do Если D0 доминирует над Di или Di доминирует над Do, то Di включается в ту же группу "привилегированных" гипотез, что и Do Эта группа должна рассматриваться программой в первую очередь.
В противном случае Д включается в другую группу гипотез, анализ которых откладывается на будущее.
Рациональное зерно в таком разделении в том, что модели, включенные в привилегированную группу на любом этапе уточнения, можно считать взаимно исключающими альтернативами. Такое заключение основано на том, что для любых гипотез (моделей) Di и Dj в этой группе диагноз, включающий Di иDj, добавит очень немного или не добавит ничего к "полноте накрытия" каждой из гипотез Di и Dj по отдельности. На следующем этапе уточнения модели обрабатываются по той же методике, если проблема выбора среди моделей, связанных с Do, будет решена. Разделение начинается с нового узла Do, который получит наивысшую оценку среди уточняемых моделей.
Уже после ввода первой порции исходных данных будет активизирована только часть всех узлов дерева. Теперь задача программы состоит в том, чтобы преобразовать дерево из исходного состояния в состояние решения. В состоянии решения дерево должно включать только те терминальные узлы, которые в совокупности "накрывают" все имеющиеся симптомы.
Разделив модели заболеваний, программа может использовать ряд альтернативных стратегий, которые выбираются в зависимости от количества обрабатываемых гипотез.
Весь процесс носит итеративный характер.Данные, которые пользователь вводит в ответ на вопросы программы в любом из перечисленных режимов, обрабатываются по той же методике, что и введенные сразу после начала сеанса работы с программой. При этом, в частности, активизируются новые узлы дерева, обновляется активизация ранее проанализированных узлов, формируются и сортируются модели заболеваний и выбираются узлы (возможно, новые) для формирования уточняющих вопросов.